i18n console output in C
Most console applications start with the basics- no usage of gettext, English-only output, no need for aligned table columns. When this is a personal pet project, it isn’t a big deal, but once your application starts getting used on a widespread basis, i18n becomes an almost necessary requirement.
In pacman, Arch Linux’s package manager, we are all in with gettext and the entire application (outside of debug-only messages) can be translated. Our Transifex project page shows we currently can show output in 26 different languages, which is quite impressive.
Unfortunately, not all languages behave the same as English, where the following assumptions are usually considered to be true:
- All characters are valid 7-bit ASCII, 8-bit ISO-8859-1 (Latin-1), or 8-bit UTF-8
sizeof(byte) == sizeof(single character)- All characters have a width of one
When the above assumptions are broken by non-English text, terrible formatting can result if you try to wrap things at screen boundaries or align things into columns.
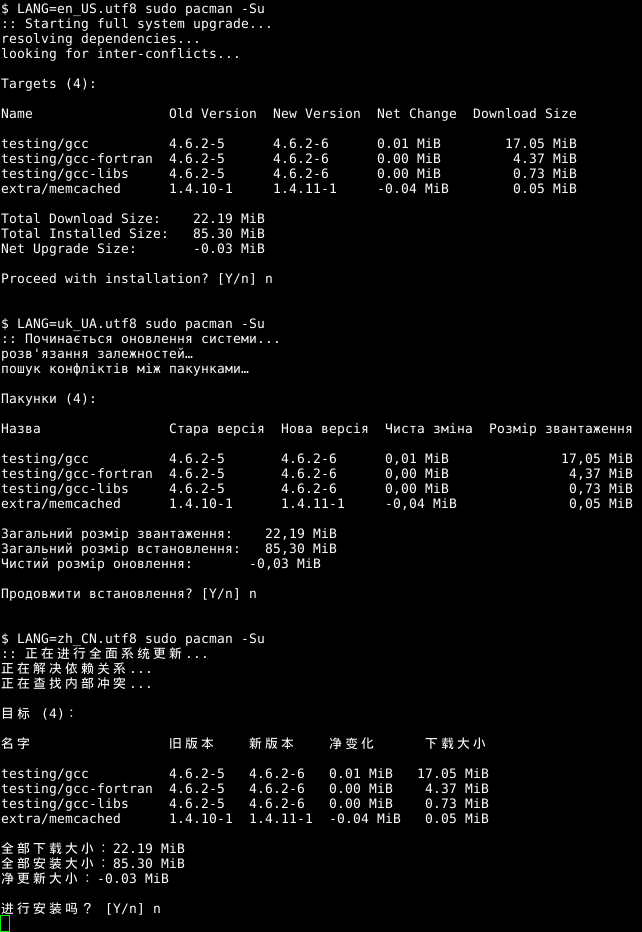
Note: the inline <pre/> tags here don’t display the output exactly as it is in a terminal. Notably, the Chinese character spacing is not quite right, so the table headers do not line up. Click the thumbnail to see how it should appear in the terminal. You can also get the UTF-8 text version and view it on your own machine.
English (all 7-bit ASCII characters):
Targets (4):
Name Old Version New Version Net Change Download Size
testing/gcc 4.6.2-5 4.6.2-6 0.01 MiB 17.05 MiB
testing/gcc-fortran 4.6.2-5 4.6.2-6 0.00 MiB 4.37 MiB
testing/gcc-libs 4.6.2-5 4.6.2-6 0.00 MiB 0.73 MiB
extra/memcached 1.4.10-1 1.4.11-1 -0.04 MiB 0.05 MiB
Total Download Size: 22.19 MiB
Total Installed Size: 85.30 MiB
Net Upgrade Size: -0.03 MiB
Ukrainian (Cyrillic, each character encoded as two bytes in UTF-8):
Note: the last line was translated misaligned as shown.
Пакунки (4):
Назва Стара версія Нова версія Чиста зміна Розмір звантаження
testing/gcc 4.6.2-5 4.6.2-6 0,01 MiB 17,05 MiB
testing/gcc-fortran 4.6.2-5 4.6.2-6 0,00 MiB 4,37 MiB
testing/gcc-libs 4.6.2-5 4.6.2-6 0,00 MiB 0,73 MiB
extra/memcached 1.4.10-1 1.4.11-1 -0,04 MiB 0,05 MiB
Загальний розмір звантаження: 22,19 MiB
Загальний розмір встановлення: 85,30 MiB
Чистий розмір оновлення: -0,03 MiB
Chinese (each character encoded as three bytes in UTF-8, display width two columns):
目标 (4):
名字 旧版本 新版本 净变化 下载大小
testing/gcc 4.6.2-5 4.6.2-6 0.01 MiB 17.05 MiB
testing/gcc-fortran 4.6.2-5 4.6.2-6 0.00 MiB 4.37 MiB
testing/gcc-libs 4.6.2-5 4.6.2-6 0.00 MiB 0.73 MiB
extra/memcached 1.4.10-1 1.4.11-1 -0.04 MiB 0.05 MiB
全部下载大小:22.19 MiB
全部安装大小:85.30 MiB
净更新大小:-0.03 MiB
To format the above correctly, the right question to be asking is “When I show this string, how wide will it be?” In C, as far as I know, this takes at least two steps: first, converting from a UTF-8 sequence of bytes to a wide character string; second, determining the width of that wide character string. The code for this two-step conversion can be seen below.
static size_t string_length(const char *s)
{
int len;
wchar_t *wcstr;
if(!s || s[0] == '\0') {
return 0;
}
/* len goes from # bytes -> # chars -> # cols */
len = strlen(s) + 1;
wcstr = calloc(len, sizeof(wchar_t));
len = mbstowcs(wcstr, s, len);
len = wcswidth(wcstr, len);
free(wcstr);
return len;
}
Luckily, we have the luxury of assuming every string we have to deal with is UTF-8, and we only really concern ourselves with UTF-8 output, or there would be a whole second level problems and method calls (such as iconv) to deal with.
See Also
- Unstated coding style - December 21, 2011
- C, unsigned integers, and the infinite for loop - July 19, 2011
- Road to pacman 3.2.0 - February 28, 2008
- Valgrind 3.3.0 and the new massif - January 23, 2008
- Using gcov for code coverage testing - December 2, 2007